


Here is the problem: You're tasked with decommissioning a database from a production AWS Application written with CDK and CloudFormation StackA. Should be straightforward, right? Take a snapshot, delete the resource, deploy, and call it a day. But then CloudFormation returns an error message:
"Resource cannot be deleted because StackB is using it."
The stack will go to UPDATE_ROLLBACK_COMPLETED in the best case. It is a starting point where we can break the dependency of StackB to StackA
Welcome to the world of CDK stack dependencies – where the convenience of automatic cross-stack references becomes a nightmare when you need to make changes.
I recently encountered this exact scenario while working with a client on a complex serverless application built with approximately 10 interconnected CDK stacks. What started as a simple database decommission turned into a deep dive into CloudFormation dependency management and a learning journey in why explicit is often better than automatic.
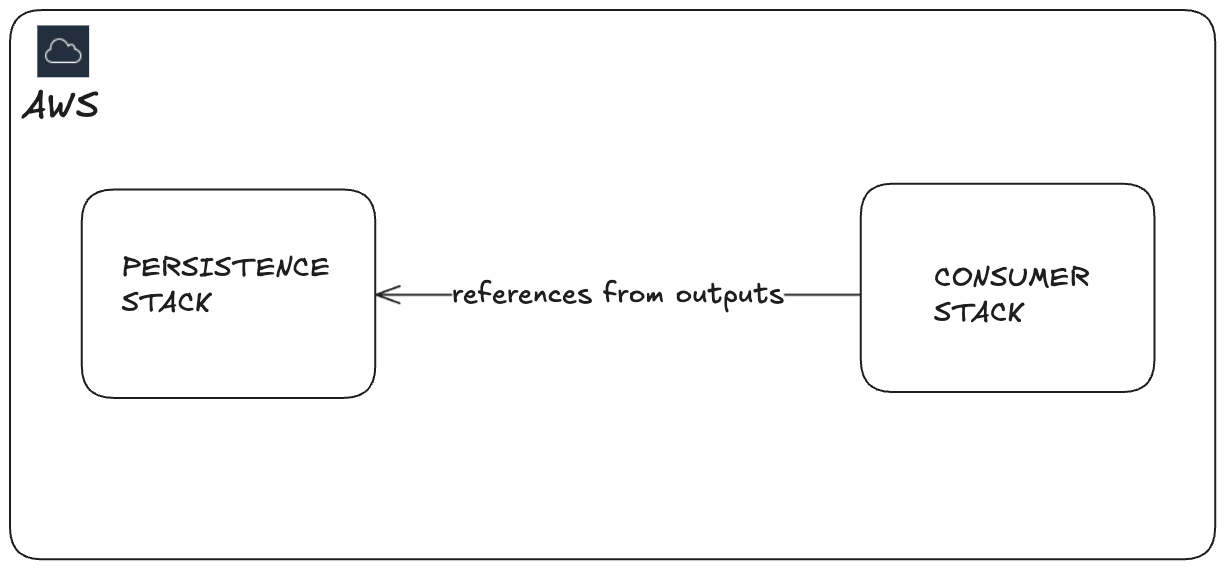
CDK makes cross-stack references incredibly easy. You expose constructs from one stack, reference them in another, and CDK automatically creates the necessary CloudFormation outputs and imports. It's elegant, it's seamless and you are not thinking about it. In the code you write it like this.
import * as cdk from 'aws-cdk-lib';
import { Construct } from 'constructs';
import * as dynamodb from 'aws-cdk-lib/aws-dynamodb';
export class PersistenceStack extends cdk.Stack {
public readonly dynamoDB: dynamodb.Table;
constructor(scope: Construct, id: string) {
super(scope, id);
// DynamoDB table for books
this.dynamoDB = new dynamodb.Table(this, 'BooksTable', {
tableName: 'Books',
partitionKey: { name: 'id', type: dynamodb.AttributeType.STRING },
billingMode: dynamodb.BillingMode.PAY_PER_REQUEST,
removalPolicy: cdk.RemovalPolicy.DESTROY,
stream: dynamodb.StreamViewType.NEW_AND_OLD_IMAGES,
});
}
}When you deploy your application the PersistenceStack will have these outputs.
[
[
{
"OutputKey": "ExportsOutputFnGetAttBooksTable9DF4AE31StreamArn345B3329",
"OutputValue": "arn:aws:dynamodb:<region>:<account>:table/Books/stream/2025-07-24T14:16:02.647",
},
{
"OutputKey": "ExportsOutputFnGetAttBooksTable9DF4AE31Arn35C1AC8F",
"OutputValue": "arn:aws:dynamodb:<region>:<account>:table/Books",
},
{
"OutputKey": "ExportsOutputRefBooksTable9DF4AE3118421EBA",
"OutputValue": "Books",
}
]
]The issue arises when you need to modify or delete the source resource in PersistenceStack there will be an issue. If you are lucky - the CDK will prevent doing it while you are trying to deploy it. However, in my case I was stuck with no possibility to change the main stack (PersistenceStack). In the CloudFormation of StackB these outputs will be used like this.
"BookDescriptionFunction8402F708": {
"Type": "AWS::Lambda::Function",
"Properties": {
"Code": {
"S3Bucket": "<bucket-name>",
"S3Key": "fa0f52f5d9fee4715ea8c160eea502cc390c5df64787152cb87118f395032c2e.zip"
},
"Environment": {
"Variables": {
"BOOKS_TABLE_NAME": {
"Fn::ImportValue": "PersistenceStack:ExportsOutputRefBooksTable9DF4AE3118421EBA"
},
"REGION": "eu-west-1"
}
},
"Handler": "index.handler",
"Runtime": "nodejs22.x",
"Timeout": 300
},
}The core challenge: CDK's automatic inter-stack dependency management prioritizes convenience over flexibility and loose coupling.
Here's the systematic approach I developed to break free from these dependency cycles, with some help from AI tools to speed up the detective work:
If you're getting deletion errors, resist the urge to force through changes. Instead:
This is where tools like Cursor become invaluable. It should also work in Claude Code. Use this prompt pattern:
"Find all stacks using <resourceA> from <stackA>. Go into these stacks
and figure out which properties are used from <resourceA>. Give me a table."
The AI will scan your codebase and create a dependency map showing exactly which properties each dependent stack is consuming. Usually, it's just 1-2 properties per stack – much more manageable than it initially appears. Now you will have the understanding of what used where.
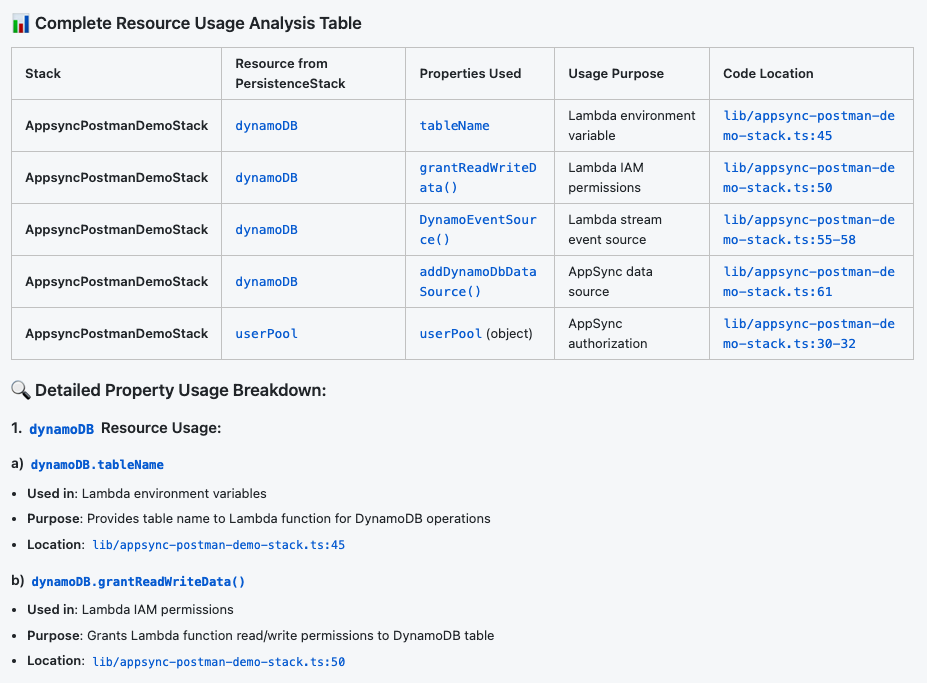
Armed with your dependency map, create explicit CfnOutput statements in your source stack for each property being consumed:
new CfnOutput(this, 'DatabaseArn', {
value: this.dynamoDb.tableArn,
exportName: 'MyApp-Database-ARN'
});Important: Do not delete the original exposed construct yet. Deploy these outputs first and verify they match the automatic ones in CloudFormation.
Replace direct construct references with Fn.importValue() calls in your dependent stacks:
const dynamoDBArn = Fn.importValue('MyApp-DynamoDB-ARN');
Pro tip: Export names must be unique across your AWS account, so establish a naming convention early.
Sometimes you don't want to refactor large amounts of code. Consider these alternatives:
resource.grantWrite(lambda), use IAM policies with ARNsThe biggest challenge I encountered was tracking down manually created security group rules. These often don't show up in your CDK code but create real CloudFormation dependencies. ClickOps is never the answer – document everything in code, even if it means importing existing manual configurations. IaC is a self-documenting entity which also manages the state of your infrastructure.
Consider using ARN-based permissions instead of CDK's convenient .grant*() methods for cross-stack scenarios:
// Instead of this:
database.grantWrite(lambdaFunction);
// Use this for cross-stack scenarios:
lambdaFunction.addToRolePolicy(
new PolicyStatement({
actions: ['dynamodb:PutItem', 'dynamodb:UpdateItem'],
resources: [`arn:aws:dynamodb:${region}:${account}:table/MyTable`]
})
);This approach gives you more control and reduces dependency coupling.
This experience reinforced a fundamental principle: design your infrastructure for change from day one. While CDK's automatic dependency resolution is powerful, explicit dependency management gives you the control you need for long-term maintainability.
Consider establishing these patterns early in your CDK projects:
Have you encountered similar CDK dependency challenges?
Let's continue discussion in LinkedIn or schedule a call with me to solve your cloud challenges. Follow me for regular deep-dives into the real-world challenges of modern cloud development in LinkedIn.